
dbt has been growing exponentially since its launch in early 2016. The creator of the tool, dbt Labs, announced in February 2022 that it had raised $222 million in Series D financing at a valuation of $4.2 billion. The company also disclosed its large and growing user base of 9,000 companies using dbt on a weekly basis, its Slack community of 25,000 members, and that 1,800 companies use its paid service, dbt Cloud.
dbt Cloud is the company’s cloud-hosted version of its open source dbt Core offering. While dbt Cloud offers a free “Developer” plan, the tier only allows for one developer seat per account, and within each account, you are limited to one project only. The next tier up is the “Team” plan, which allows for up to 8 users, but which comes at a price of $100 per seat per month.
That cost may be negligible for large enterprises, but for small and mid-sized companies, it requires at least a conversation and a logical rationale for subscribing to it. dbt Cloud is a lovely product, but given the free alternative of dbt Core relative to the benefits, I struggle to find a reason to use it other than “we can afford it, so why not”.
In my view, there are only two reasons to use dbt Cloud, which are the following:
- The ability to use a graphical user interface (vs. command line)
- It’s deployment as a cloud-based platform (vs. desktop/laptop)
Using a graphical user interface (GUI) vs. the command line is a matter of personal preference, and deciding which to use is a topic of its own. Unfortunately, I think most people in general use GUI’s due to a lack of familiarity (and/or possibly a fear) of the command line, and ultimately, are doing themselves a disservice. Point-and-click interfaces are much less efficient in many situations, including with data transformation. dbt already requires knowledge of SQL, git, and navigating a multitude of text files. There’s not much of a leap beyond that to learn how to use dbt Core with the command line. Said differently, dbt Cloud is not a no-code solution and still requires SQL scripting. If you are comfortable writing code, you can easily learn to type a few commands on the command line.
With respect to running dbt in the cloud, that is an absolute must. ou shouldn’t run a production data transformation processes on a personal computer connected to the Internet via an office or home network. That is just an invitation for recurring failures. The most reliable way to run production transformations is somewhere in the cloud, where computers are managed by someone else whose full time, 24/7 job is to keep that compute resource plugging in and connected to the Internet.
For the longest time, I thought that the best place to run dbt Core was on a Linux server in DigitalOcean. I can deploy a server there for $12/month that multiple users can access, and which can be easily secured and locked down with built-in firewall capabilities. The server is always on. Transformation jobs can be setup with Linux’s built-in job scheduler (cron). Other jobs can also be added to the same server, including data loading scripts, which in fact cannot be run on dbt Cloud at all. dbt Cloud only helps with the T part of ETL (transformation), but not the L part (loading of data).
While a traditional Linux server can be an extremely cost effective, simple, and efficient way to maintain a data pipeline, the downside to a traditional server is, funny enough, the server itself. A server requires periodic maintenance, primarily security updates, especially since it is typically exposed directly to the Internet. Although, a firewall and digital login keys should be enough to lock down a server, there’s always a non-zero chance that the server could be hacked. Although I have played with “serverless” alternatives many times, including AWS Lambda, Azure Functions, Google Cloud Run, and Docker Containers, as well as other ETL orchestration tools like Azure Data Factory and Azure Databricks, I found the burden and complexity of the setup to be too cumbersome. As I often transition the data pipelines I build to clients to maintain, training someone in any of the above mentioned tools would be extremely time intensive, and not to mention very intimidating.
As evidence, here is one article actually describing how implementing dbt as an AWS Lambda function “isn’t worth it“. Here is another example of the complexity required for what is supposed to be a “Clean” solution of running dbt with Azure Data Factory. After some additional research, I came across this article on implementing dbt as an Azure Function, which was still fairly complex and suggested using Azure Queue Storage, Docker Containers, as well as Azure DevOps Pipelines. However, this article led me to search for an even simpler solution: Azure DevOps Pipelines standalone without any frills.
As a result, I came up with this extremely simple and free way to run dbt in the cloud using Azure DevOps Pipelines that requires just a single additional text file that I named pipelines.yml:
trigger:
branches:
include:
- main
pool:
vmImage: 'ubuntu-22.04'
schedules:
- cron: "0 0 * * *"
displayName: Daily UTC build
branches:
include:
- main
always: true
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.9'
- bash: |
pip install dbt-snowflake==1.5.0
dbt debug --profiles-dir .
dbt run --profiles-dir .
displayName: 'Install and run dbt'
env:
SNOWFLAKE_ACCOUNT: $(SNOWFLAKE_ACCOUNT)
SNOWFLAKE_USERNAME: $(SNOWFLAKE_USERNAME)
SNOWFLAKE_PASSWORD: $(SNOWFLAKE_PASSWORD)
SNOWFLAKE_ROLE: $(SNOWFLAKE_ROLE)
SNOWFLAKE_DATABASE: $(SNOWFLAKE_DATABASE)
SNOWFLAKE_SCHEMA: $(SNOWFLAKE_SCHEMA)
SNOWFLAKE_WAREHOUSE: $(SNOWFLAKE_WAREHOUSE)Below is a walk-through of what the pipelines.yml file is doing. Think of this file as an instruction set for Azure DevOps Pipelines to execute using cloud resources:
trigger:Instructs Azure DevOps Pipelines to watch for changes to themainbranch and run the pipeline configured above upon editspool:When running the pipeline, use this specific Linux image (Ubuntu 22.04) to ensure consistency in executionschedules:Sets a scheduled job using standard cron notationsteps:Requests that Azure DevOps Pipelines uses a specific Python version (3.9) for consistency, installs dbt Core, validates the database connection, and runs the dbt transformation with environment variables from theenv:section
There is one other file required in the implementation. The profiles.yml file that is normally saved in a hidden folder in the home directory of a given dbt Core installation should also be saved inside of the dbt project, except that we should replace hardcoded values with environment variables to avoid saving passwords within the code base. Here is the file:
dbt_azdevops:
outputs:
dev:
type: snowflake
account: "{{ env_var('SNOWFLAKE_ACCOUNT') }}"
user: "{{ env_var('SNOWFLAKE_USERNAME') }}"
password: "{{ env_var('SNOWFLAKE_PASSWORD') }}"
role: "{{ env_var('SNOWFLAKE_ROLE') }}"
database: "{{ env_var('SNOWFLAKE_DATABASE') }}"
schema: "{{ env_var('SNOWFLAKE_SCHEMA') }}"
warehouse: "{{ env_var('SNOWFLAKE_WAREHOUSE') }}"
threads: 1
target: devThis example provided connects to a Snowflake data warehouse, but you can just as easily use Google BigQuery or other data warehouse platforms.
Once the pipelines.yml and profiles.yml are saved to the root folder of the dbt project and committed to the repo (see below), we now have to set up the Azure DevOps Pipeline using the DevOps portal and point to the pipelines.yml in the repo.
Here’s how to do that. First, navigate to the Pipelines tab:
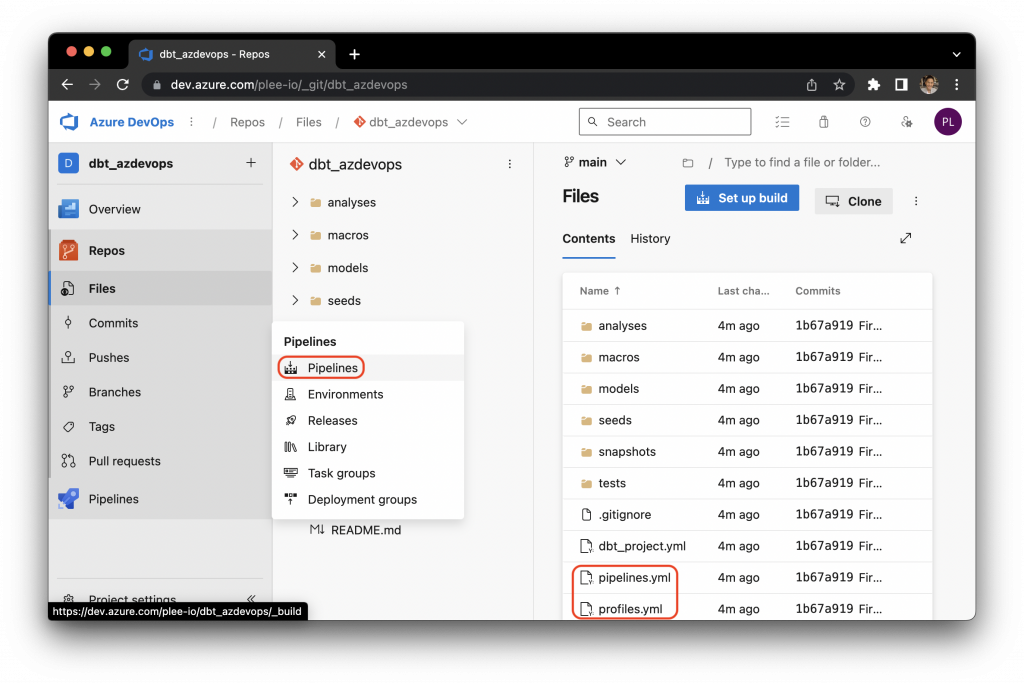
Click on “Create Pipeline” to create your first pipeline:
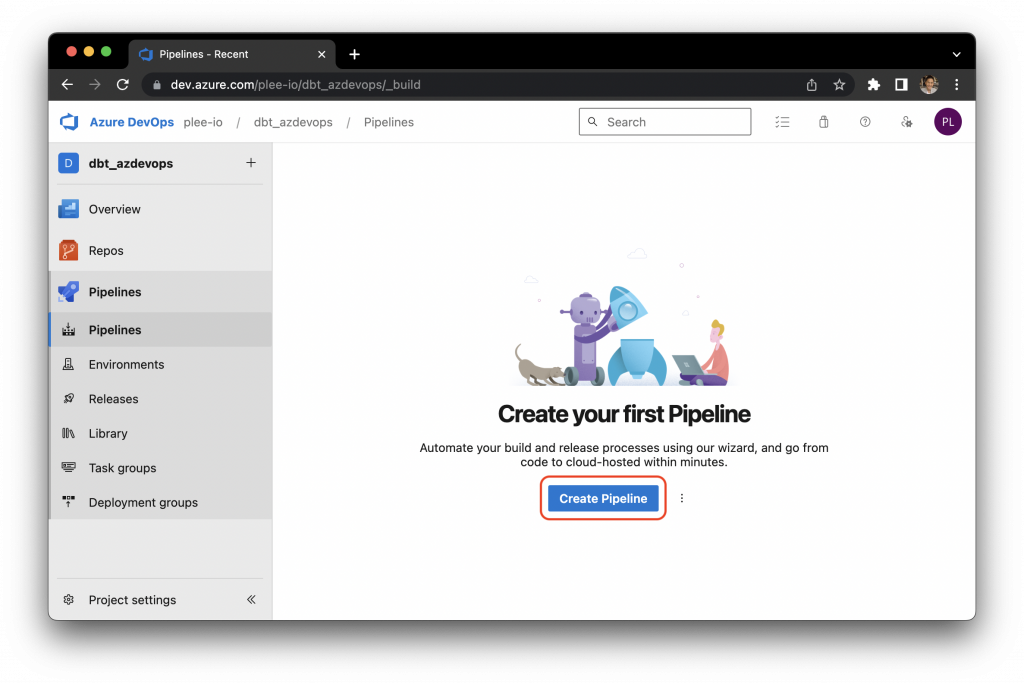
Select “Azure Repos Git” (or your git provider):
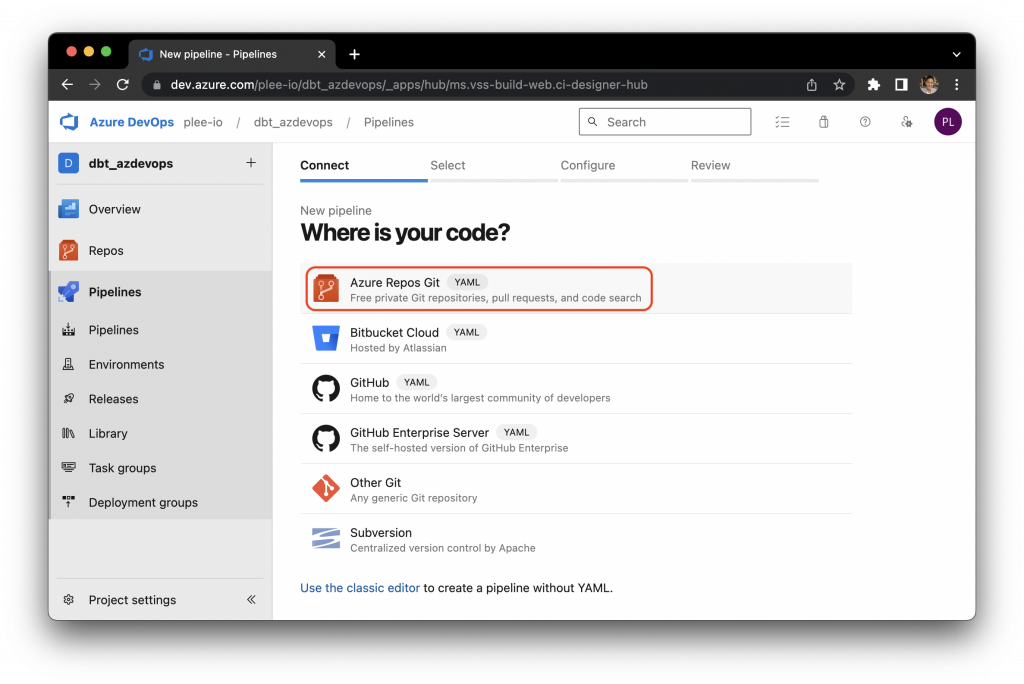
Select “Existing Azure Pipelines YAML file” and choose the pipelines.yml that we created:
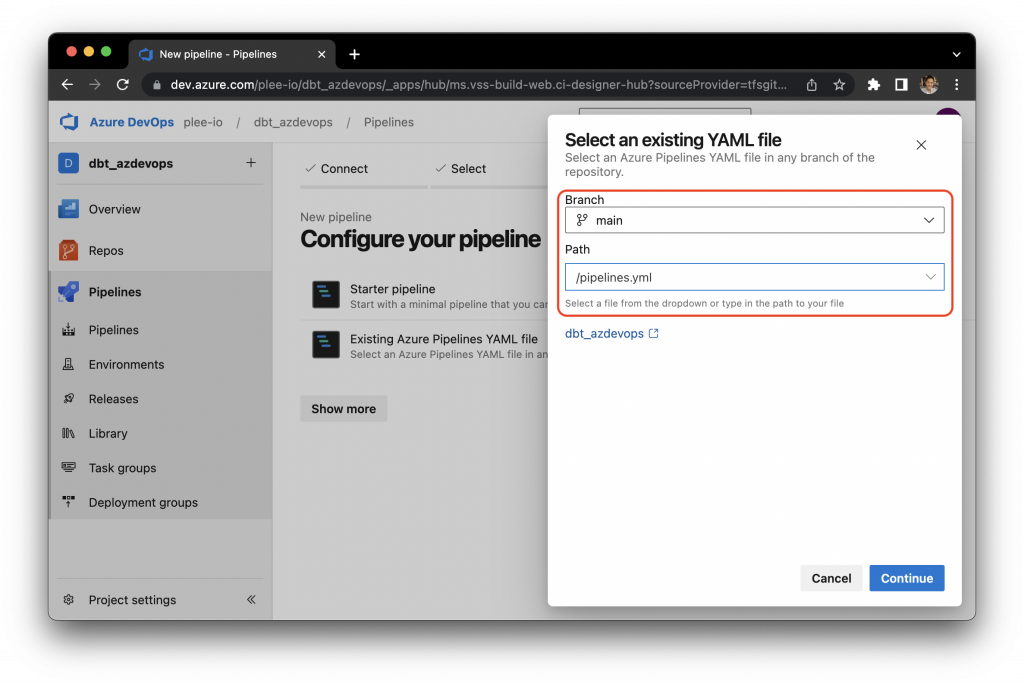
Recall that to avoid saving passwords and sensitive database information to the code repo, we reference environment variables instead, and therefore, we need to enter those environment values into Azure DevOps Pipelines. To do that, click on the “Variables” button:
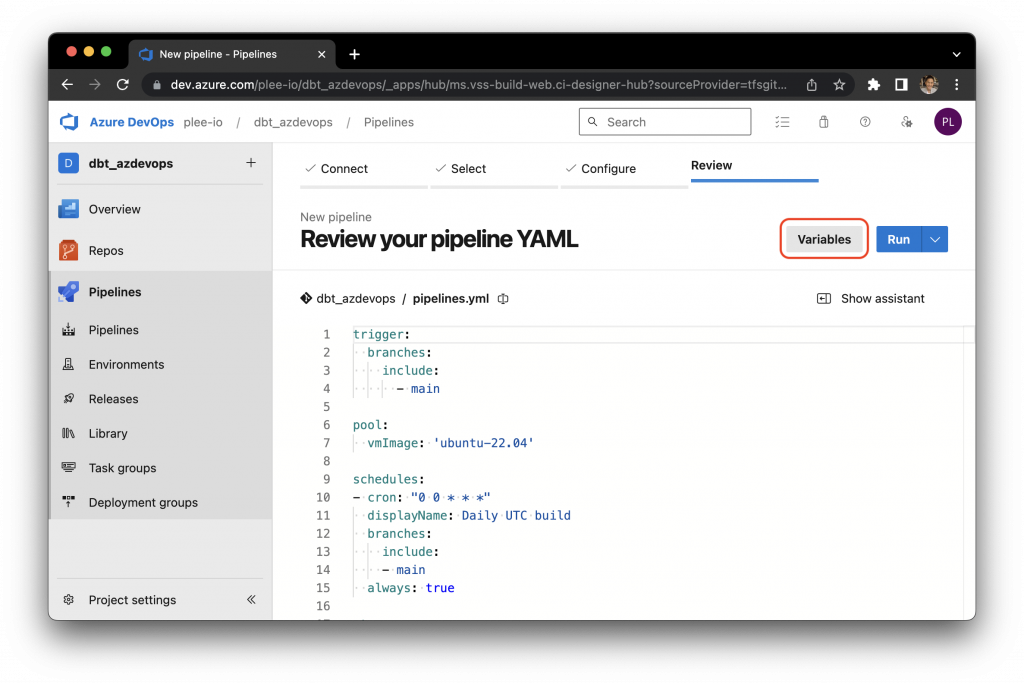
Enter all of the environment values listed in the profiles.yml file. Azure DevOps Pipelines is able to store passwords securely:
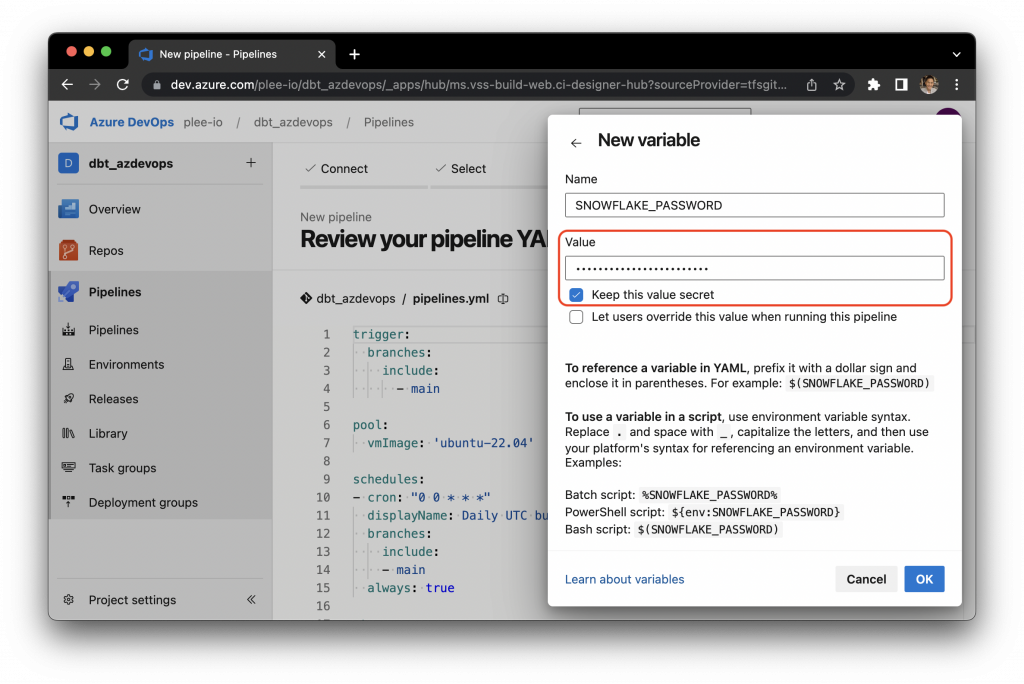
Once all of the environment variables have been entered, click on “Save”:
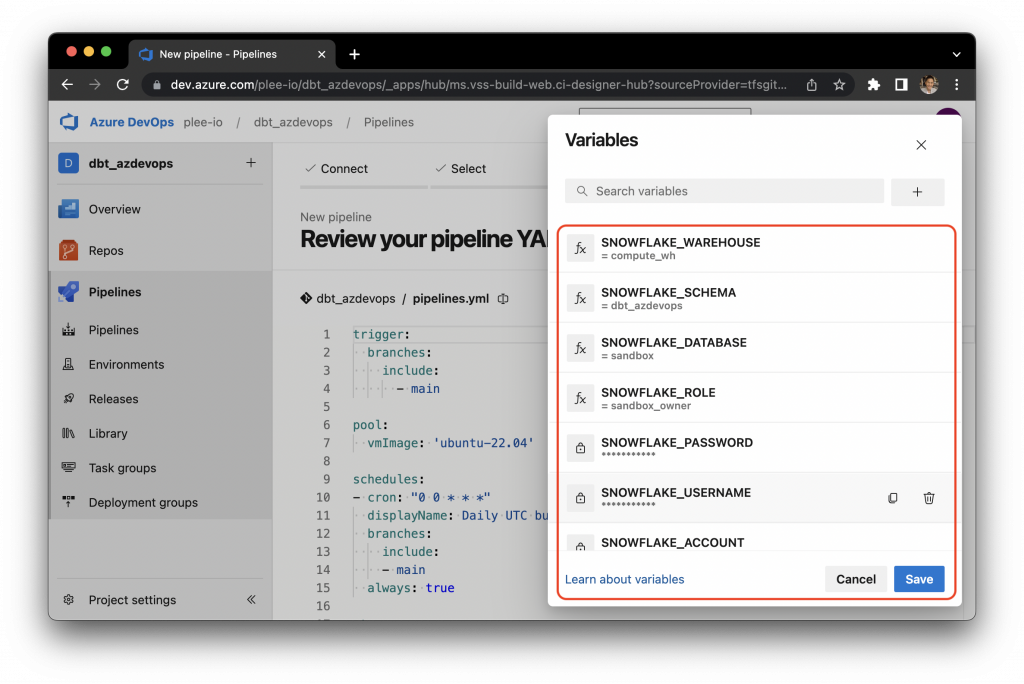
Finally, click “Run” and view the progress of the job you just started. You will be able to see logs of the pipeline running within the portal.
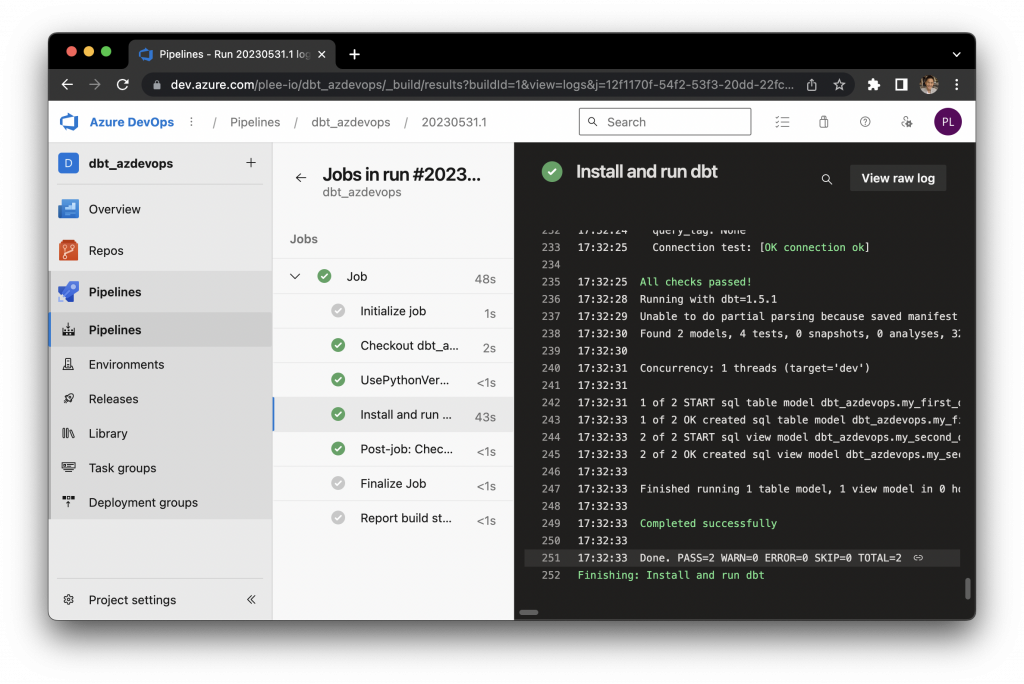
Congratulations, you have now implemented a simple and free alternative to dbt Cloud that runs on a schedule. Any changes that you push to the repo will also trigger the pipeline, essentially running dbt Core in the cloud.
The example pipelines.yml was provided as a quick way to get started; however, you could customize it even further for various environments, including a test and production environment.